

Estimer le coût d'un projet IA : comment éviter les pièges et choisir un prestataire sérieux
Guide IA pour dirigeant innovant (Partie #4)
Avant de mettre sur le marché une fonctionnalité basée sur des technologies d'Intelligence Artificielle, il faut la concevoir.
Comme pour tout projet technologique, deux questions se posent inévitablement : combien cela va-t-il coûter (d'abord), puis combien cela a-t-il coûté (ensuite).
Comment une équipe technique peut-elle estimer au mieux le coût et la durée d'un projet basé sur l'IA ? Comment des dirigeants peuvent-ils vérifier le sérieux et la fiabilité des estimations qui leur sont proposées ?
Vastes questions.
Tout d’abord, pourquoi est-ce important ?
Avoir une idée de ce qu'un projet peut rapporter ne suffit pas pour le lancer. Il est généralement nécessaire d'estimer les coûts et de s'organiser : quand pourra-t-on lancer le produit, quel budget doit-on négocier ou lever, à quel prix devrait-on payer ce prestataire ?
Ni les dirigeants, ni les investisseurs, ni l'équipe métier ne possèdent les compétences nécessaires pour répondre à ces questions. Ils font donc appel à un expert technique, et lui demandent des estimations.
Ça l’embête profondément, l’expert technique. Ça prend du temps, c'est un exercice périlleux, rempli d'incertitudes, et il sait que ses estimations seront ensuite revendues comme des échéances, qui risquent de mettre l'équipe de réalisation en difficulté si elles sont trop ambitieuses.
Ça l’embête, mais il sait que c'est son rôle de répondre. Lorsque vous souhaitez refaire votre toit, qui de plus légitime que le charpentier pour estimer la durée des travaux ? Quand on s'adresse à un expert, on s'attend à ce qu'il soit capable de se projeter et d'anticiper les délais.
1. Comment rater ses estimations le moins possible (elles ne seront jamais parfaites)
La loi de Hofstadter rappelle avec humour que les projets prennent toujours plus de temps que prévu. Pour calculer la durée de conception d'un projet complexe, il faut selon lui doubler sa durée estimée en prenant l'unité supérieure. Ainsi, un projet de deux mois prendrait quatre ans, et un travail de quatre jours nécessiterait huit semaines.
Une étude du Harvard Business Review enfonce le clou, en révélant qu’un projet informatique sur six dépasse le budget initial de 200%.
Alors quoi, on abandonne ? Ou on essaie d’estimer correctement ?
D'abord, diviser pour mieux estimer
Pour estimer un projet, une méthode fréquemment utiliser consiste à la découper. Rien de sorcier, nous cherchons à réduire une complexité abstraite en plusieurs objets spécifiquement mesurables.
Si nous souhaitons identifier des pièces défectueuses dans une usine d'assemblage, le problème peut être divisé en quatre tâches :
- Préparer le jeu de données
- Choisir et entraîner le modèle
- Déployer le modèle en production
- Monitorer les performances
Pouvons-nous estimer le projet à ce stade ? Pas vraiment. Nous devons affiner la granularité en subdivisant chaque tâche.
Par exemple, la préparation du jeu de données peut être décomposée en :
- Définir la source et les propriétés du jeu de données
- Collecter les données
- Étiqueter les données
- Gérer le stockage des données
Anticiper la durée totale du projet serait très complexe. Estimer la durée d’une sous-tâche telle que l'étiquetage des données est plus accessible, il suffit de connaitre le volume de données à étiqueter.
Ensuite, mesurer la complexité
Un ingénieur peut dire qu'il a besoin de coder quatre jours pour développer la fonctionnalité X. Il ne code cependant pas du lever au coucher du soleil. Il participe à des réunions, effectue des recherches sur un problème, fait de la veille, compare différentes solutions techniques et attend la validation du comité d'intégration avant de déployer en production.
Les estimations doivent prendre en compte ces tâches connexes. Pour le faire, Ruben Sitbon (Solution Architect chez Sipios) s’appuie sur le modèle des trois niveaux de complexité mis en avant par Arnaud Lemaire, et tiré de « there is no silver bullet », une nouvelle de Frederick P. Brooks.
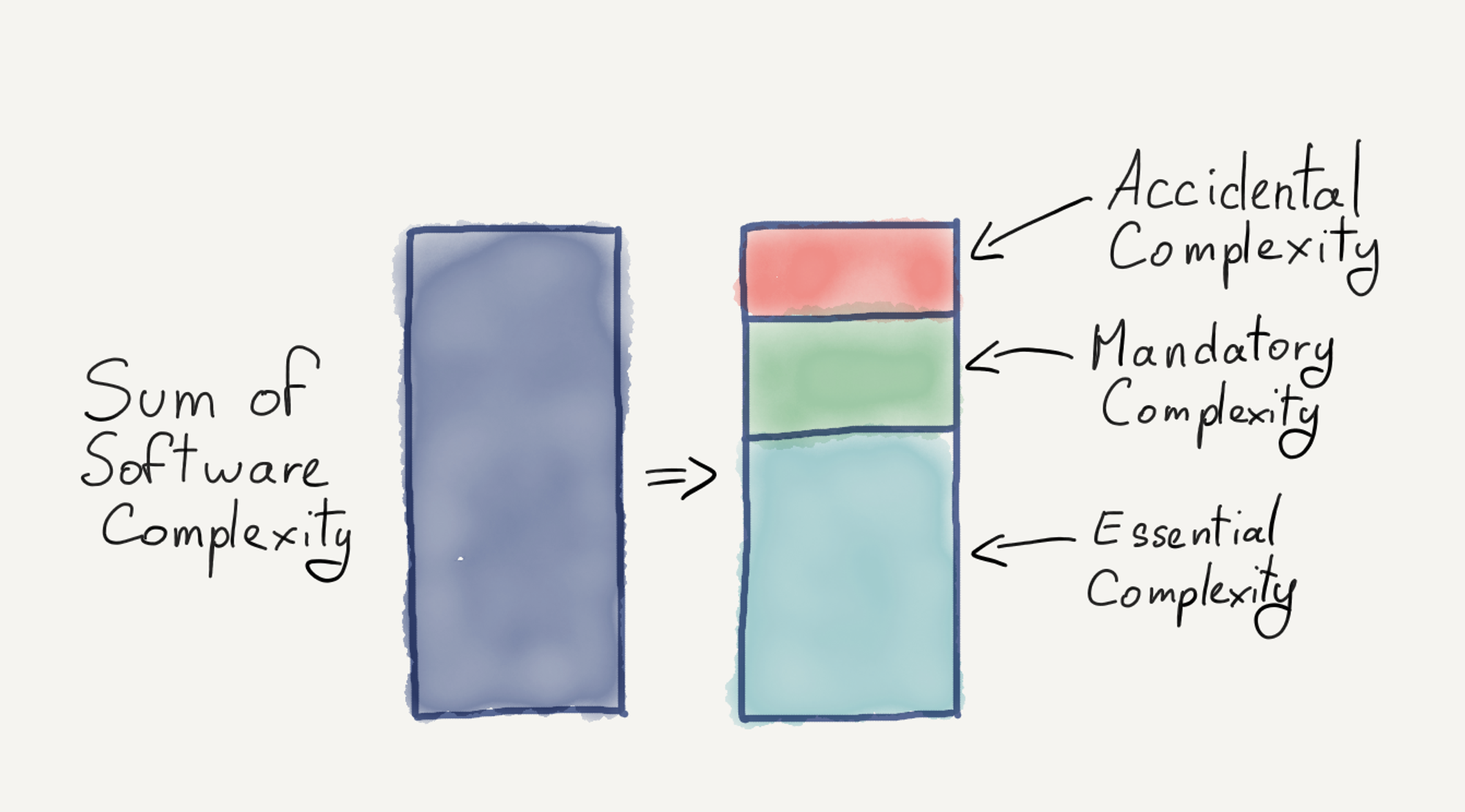
Image d’Arnaud Lemaire, 14 mai 2020
- Complexité essentielle : d'abord, nous estimons le temps nécessaire pour résoudre le problème de la manière la plus pragmatique, sur notre ordinateur, sans contrainte.
Nous cherchons à estimer la durée d'une fonctionnalité F, appelons cette durée d(F). Pour réaliser F sur notre ordinateur et sans contrainte, il faut réaliser deux tâches : X et Y. Nous estimons la durée de chaque tâche, respectivement d(X) et d(Y).
Calcul de la complexité essentielle : d(F.essentielle) = d(X) + d(Y) - Complexité obligatoire : ensuite, nous estimons les tâches nécessaires pour que le logiciel puisse fournir le service attendu. Arnaud Lemaire l'explique bien : "Si vous codez une API de paiement pour une plateforme web, vous aurez besoin d'un serveur HTTP. Ce serveur HTTP ne fait pas partie de la complexité essentielle (qui est liée au système de paiement), mais il est obligatoire pour que votre application soit utile". Pour anticiper la complexité obligatoire chez un nouveau client, les DORA metrics sont un bon indicateur de mesure de la performance d’une équipe (fréquence de déploiement, délai de mise en production, taux de changements echoués, temps de restauration).
La complexité obligatoire peut par exemple être exprimée avec un coefficient multiplicateur, entre 0 et 1.
Pour la fonctionnalité F, nous identifions plusieurs tâches connexes, et savons que les DORA metrics de l'entreprise sont mauvaises. Nous évaluons (subjectivement) le coefficient multplicateur à 0,8.
Calcul de la complexité obligatoire : d(F.obligatoire) = d(F.essentielle) * 0,8 - Complexité accidentelle : enfin, nous identifions les domaines où l'équipe manque d'expertise et où des défis inattendus peuvent survenir. Il y a toujours des inconnues, nous avons pourtant tendance à estimer uniquement ce que nous connaissons. La complexité accidentelle nous aide à estimer ce que nous ne connaissons pas : nous en déduisons une marge acceptable et suffisante pour les dépassements éventuels.
Pour la fonctionnalité F, nous sommes en maitrise : nous avons développé la même fonctionnalité chez un client concurrent. Notre seule crainte est que c'est la première foire que notre Tech Lead va encadrer un développeur junior. S'il a du mal avec l'exercice, ça nous ralentira.
Estimation (subjective) de la complexité accidentelle : d(F.accidentelle) = x jours
d(F) = d(F.essentielle) + d(F.obligatoire) + d(F.accidentelle)
Si c'est trop exploratoire, comparer à ce que l’on connait
Même pour des projets de R&D ou non déterministes, la plupart des actions peuvent être décomposées en tâches déterministes, donc estimables, et cette incertitude peut être prise en compte lors de l'estimation de la complexité.
Cependant, dans la pratique, les durées dépendent de nombreuses variables et d’itérations dont les résultats sont imprévisibles. Interrogée sur le sujet, Louise Naudin (Entrepreneuse, experte Deep Learning et NLP) considère que “plus nous cherchons à diviser, plus nous obtenons du précisément faux. C’est utile pour vendre un projet, mais ça ne reflète pas la réalité”.
Pour ces projets exploratoires, elle recommande plutôt de prendre comme base la durée de projets similaires déjà réalisés, d’en isoler les différences et d’évaluer leur impact. Chaque delta identifié permet d’ajuster cette base à la hausse ou à la baisse.
Attention au dimensionnement, une équipe deux fois plus grande ne va pas deux fois plus vite
Lorsque la question de la taille de l'équipe se pose, certains pensent qu'il suffit de multiplier le nombre d'individus pour diviser le temps. Ceux qui ont déjà travaillé avec des équipes de cent développeurs vous le confirmeront : l'apport marginal d'un développeur n'entraîne pas une augmentation proportionnelle de la vélocité.
En d'autres termes, cinq développeurs ne vont pas cinq fois plus vite qu'un développeur seul. Certaines tâches peuvent être parallélisées, mais pas toutes. Et plus l'équipe grandit, plus il faut d'énergie pour canaliser et gérer les dépendances.
2. Comment challenger des estimations quand on n'a pas un profil technique
Défier des estimations sans avoir de connaissances techniques, uniquement sur la base de son intuition, peut sembler intimidant.
Dans un monde idéal, les profils "tech" et "business" devraient travailler en confiance. Mais il peut être difficile de faire confiance, par exemple dans le cas d’un prestataire qu’on ne connaît pas encore.
Alors, comment remettre en question les estimations d'un projet lorsque l'on n'a pas un profil technique ? Voici trois pistes de réflexion :
Le quoi : savoir ce qu’on estime avant de l’estimer
Il peut être difficile d'obtenir une estimation précise si le prestataire de services ne maîtrise pas encore tous les aspects techniques du projet.
S’il s’engage au forfait et que le prix vous convient, le risque est de son côté. Si vous le payez à la journée, il peut être judicieux de découper le projet en deux phases distinctes, en commençant par une phase de conception (étude de faisabilité, sprint 0, pré-projet…) avant la mise en œuvre proprement dite.
Cette phase de conception permet de dérisquer le delivery et d’affiner les estimations. Selon Bratzadeh (expert IA), elle doit permettre de répondre aux questions suivantes :
- Avons-nous une compréhension globale des exigences du projet ? Existe-t-il des éléments ambigus ou évolutifs susceptibles d'affecter l'estimation ?
- Avons-nous évalué la disponibilité et l'expertise des membres de l’équipe ? Avons-nous accès aux outils, technologies et infrastructures nécessaires ?
- Quels sont les risques potentiels, techniques ou autres, qui pourraient avoir une incidence sur le calendrier et le budget du projet ? Avons-nous élaboré des plans d'urgence pour atténuer ces risques ?
- Existe-t-il des facteurs externes, tels que des intégrations de tiers, l’acquisition de jeu de données (missionner des équipes pour prendre des photos dans une usine, par exemple) ou des exigences réglementaires susceptibles d'influer sur le calendrier et le coût ?
- Avons-nous pris en compte la dette technique existante ou le code hérité qui pourrait affecter la vitesse de développement et le coût ? Prévoyons-nous du temps de refactoring ou de traitement de cette dette technique ?
- Quel est le niveau de test et de contrôle de la qualité nécessaire pour le projet, en particulier pour les composants critiques ?
Le comment : questionner la méthode plutôt que le résultat
Ruben Sitbon suggère de demander à l'expert quel modèle mental a été utilisé pour estimer le projet, et quelles hypothèses ont été prises en compte. Un développeur expérimenté aura toujours une idée du temps de développement d’une fonctionnalité, et pourra répondre “à l’instinct”. Mais quelqu’un qui s’appuie sur un modèle met ce même modèle à l’épreuve à chaque projet. Chaque écart constaté lui permet de progresser et d’affiner son modèle, améliorant ainsi ses prochaines estimations. En comprenant la logique derrière l'estimation, vous pourrez mieux évaluer sa fiabilité.
Le qui : s’appuyer sur un expert
Si vous vous lancez dans le développement de solutions d'IA, Jaser recommande de faire appel à un expert indépendant pour vous accompagner. Comme un guide expérimenté en montagne, il pourra évaluer la faisabilité du projet, anticiper les défis et trouver le meilleur chemin. Surtout, il sera capable de déterminer si une approche heuristique plus simple pourrait suffire pour obtenir le résultat recherché.
Quand le contexte le justifie, Jaser recommande d’embaucher un AI Product Manager expérimenté : “il développera une connaissance approfondie de l’entreprise, des clients et des processus, et sa responsabilité ne s'arrêtera pas une fois la solution déployée”.
3. Au delà des coûts humains, combien cela va-t-il coûter ?
La question des coûts de l'IA est complexe et dépend de plusieurs facteurs tels que le type d'IA, les technologies utilisées et les solutions d'hébergement choisies.
Prenons l'exemple de l'IA générative. Les techniques d'entraînement des modèles de langage évoluent rapidement. BloombergGPT a coûté environ 1 million de dollars, mais quelques mois plus tard, il est possible d'atteindre des performances similaires pour seulement quelques centaines de dollars avec AWS, en un après-midi (oui, l’outil a été entraîné sur quelques données propriétaires, mais 99,30% provenaient de sources disponibles au public).
Coûts d'entrainement : API ou open-source ?
Pour GPT 3.5 turbo, le coût d'entraînement est de 0,0080 $ pour chaque 1 000 tokens (avant que l’API traite les instructions, l’entrée est décomposée en morceaux de mots appelés “tokens” ; 1 paragraphe ≈ 100 jetons), soit environ 340 $ pour 21 millions de mots.
Une fois le modèle déployé, il faut faire attention, car vous payez à la fois pour les tokens de demandes et pour les tokens de contenu généré. À chaque réponse générée par l'API, OpenAI facture à nouveau l'intégralité de l'historique de la conversation, ce qui peut faire grimper les coûts rapidement.
En utilisant un modèle open-source tel que Llama 2, l'entraînement nécessite une grande quantité de mémoire (un cluster GPU de 560 Go) pour un coût d'environ 340 $ par jour sur AWS.
Selon Yann Le Cun de Meta, "opérer Llama2 70B sur Anyscale coûte moins cher que ChatGPT : 1$ par million de tokens". Mais entraîner un modèle comme Llama 2 implique d’autres coûts (hébergement, maintenance…).
Il n'y a pas de recette toute faite, mais les solutions les plus simples seront souvent les meilleures. En d'autres termes, s'il n'y a pas d'enjeu de confidentialité ni de besoin de customisation, GPT couplé à du prompting suffira à résoudre de nombreux problèmes.
Coûts d’inférence
Contrairement aux produits numériques traditionnels où chaque nouveau client coûte généralement moins cher à servir, en IA, les coûts d'inférence ont tendance à s'accumuler. Plus le modèle est complexe et plus les données sont volumineuses, plus la puissance de calcul nécessaire (CPU, GPU) augmente. Cela entraîne également des coûts de stockage plus élevés, que ce soit en local ou dans le cloud, ainsi que des coûts de maintenance, car les modèles d'apprentissage automatique nécessitent des mises à jour régulières.
Concrètement, les GPU, ça coûte combien ?
En ce qui concerne les GPU, la solution la plus simple est souvent de les louer auprès d'un fournisseur de cloud (GCP, AWS, Azure). Si vous avez des besoins de variation de charge, les options serverless sont à considérer.
Si vous préférez acheter vos propres GPU, Nvidia est le principal fabricant. Les équipements et leurs prix évoluent rapidement, mais voici quelques ordres de grandeur :
- Le modèle RTX 4090 à 1800€ est suffisant pour charger de petits modèles
- Si vous souhaitez entraîner votre propre modèle de langage, vous aurez besoin de GPU H100, d'un DGX H100 avec des CPU, de commutateurs et de SSD. Selon vos relations avec NVIDIA, vous pouvez envisager un budget d'environ 300 000 $.
- Ensuite, c’est les poupées russes : on met 32 DGH H100 dans une Scalable Unit, 4 à 64 Scalable Unit dans un DGX SuperPOD, et plusieurs DGX SuperPOD dans un Hyperscaler…

Image partagée par Vin Vashishta sur Linkedin
Dans ce marché, les marges sont élevées et de nombreux clients ne sont pas satisfaits des solutions proposées. Cela laisse présager une possible disruption, où un acteur finira par proposer LA solution qui était sous nos yeux depuis tout ce temps.
Le projet arrive à sa fin (l’article aussi). Combien cela a-t-il coûté ?
A la fin du projet, il faudrait que ce que ça a coûté soit inférieur à ce que ça devait coûter. N'est-ce pas ?
Selon le CHAOS report, édité chaque année depuis plus de quinze ans et dont les conclusions n’ont jamais changé, il existe une relation inverse entre la taille d'un projet informatique et son taux de réussite. Plus le projet est important, plus les chances de rencontrer des difficultés augmentent. Ainsi, si vous dépassez le million d'euros de projet, il est fort probable qu'il ne réussisse pas.

Standish Group 2015 Chaos Report
Estimer un projet est, de fait, un exercice inconfortable. Celui qui estime craint de s'engager sur quelque chose de trop ambitieux et de mettre l’équipe de delivery en difficulté ; celui qui commande l’estimation craint que l’équipe ne livre pas dans les temps ou qu’elle soit payée à se tourne les pouces.
Quoi qu’il arrive, rien ne se passe jamais comme prévu. Une bonne estimation prend en compte cette complexité, et un temps de conception en début de projet permet d’affiner les estimations pour prendre en compte tout changement de scope, audit de sécurité manquant ou nouvelle fonctionnalité qui n’avait pas été anticipée.
Enfin, n'oublions pas que les projets s'inscrivent dans un contexte plus global. Les équipes travaillent sur d'autres tâches, participent à des réunions, prennent des congés, tombent malades et suivent des formations. Personne ne développe vingt-quatre heures sur vingt-quatre et sept jours sur sept, à moins d'être une IA, peut-être !©
Sources
- Daixuan Cheng, Shaohan Huang, Furu Wei (2023, Sept). Adapting Large Language Models via Reading Comprehension
- Et si on redémarrait l'agilité ? (Arnaud Lemaire)
- Certaines complexités sont plus utiles que d'autres (Arnaud Lemaire)
- Why Your IT Project May Be Riskier Than You Think (Harvard Business Review)
- Your agile project needs a budget, not an estimate (Harvard Business Review)
- No Silver Bullet Essence and Accidents of Software Engineering (Frederick P. Brooks, Jr. )
- https://www.datascience.vin/
- https://en.m.wikipedia.org/wiki/Divide-and-conquer_algorithm