

Lancer un projet de deep learning, ou le mariage heureux de la recherche et du produit
Guide IA pour dirigeant innovant (Partie #3)
Le delivery - Des itérations, de la sueur et un enjeu clé : mettre en production
Comme il est d’usage dans des contextes d’incertitude, les projets de deep-learning fonctionnent en cycles courts. Chaque sprint permet d’atteindre un objectif clairement défini, avec des déploiements réguliers exposés à quelques utilisateurs, et couvre les activités suivantes :
- Préparation des données : nous explorons les sources de données et leurs relations entre elles, nous nous assurons de la qualité des données, nous construisons le pipeline d’ingestion des données, nous préparons les données et les étiquetons. Cette dernière tâche, aussi appelée “data labeling”, est dans la plupart des cas externalisée à l’étranger, avec des effets négatifs pour l’entreprise et la société en général : les entreprises clientes ne vérifient pas toujours la qualité des données étiquetées qui serviront de base à l’entrainement de leurs modèles (et impacteront directement leur performance), et l’étiquetage est souvent réalisé par des travailleurs précaires.
- Conception ou sélection du modèle, exploration, développement des fonctionnalités et test : le développement du modèle repose sur deux phases, l’entrainement du modèle (le modèle est créé, entrainé sur un dataset d’apprentissage et optimisé en ressources consommées, temps de réponse, biais et valeurs extrêmes) et son inférence (application du modèle à un échantillon de données qu’il ne connait pas, le forçant à faire preuve de déduction pour arriver à un résultat, et comparaison des résultats obtenus avec les métriques business attendues).
- Déploiement à un petit groupe d’utilisateurs, expérimentation et intégration des feedbacks, puis déploiement à large échelle, maintenance et industrialisation : si le MVP est réussi, les enjeux deviennent principalement techniques, il faut construire une équipe capable de faire vivre le projet dans la durée.
- Ne pas penser POC (celui-là était facile), mais penser MVP : s’il n’est pas encore parfait, le MVP doit répondre au problème de l’utilisateur et être viable. Dès le départ, nous devons donc produire au niveau de qualité attendu et anticiper la stratégie de mise en production.
- Se concentrer sur la qualité des données : de nombreux projets se concentrent sur le développement du modèle et négligent les données. Pourtant, si leur exploration et leur préparation prend du temps, c’est la qualité (plus que la quantité) des données qui permet d’améliorer la performance du modèle et de la tester. Sans donnée de qualité, comment savoir si le pourcentage d’erreur et dû au modèle ou aux erreurs présentes dans le dataset qui ont servi à l’entrainer ?
- Évaluer la performance réelle du produit : si l’on teste la capacité technique du modèle à réaliser des sous-taches spécifiques (par exemple apprendre au modèle Tesla à détecter un feu rouge), il ne faut pas perdre de vue la valeur finale apportée à l’utilisateur. Les métriques business, définies en début de projet, représentent le contrat à remplir par l’équipe avec des critères d’acceptation basés sur des exemples concrets (si la Tesla réalise parfaitement 99.99% de ses sous-taches spécifiques, mais qu’elle écrase un passant sur un passage piéton, la valeur utilisateur n’est pas atteinte). Le Product Owner (ou Product Manager) mesure la performance des fonctionnalités et leur progression au fil du temps, ce qui permet à l’équipe d’optimiser le modèle là où il en a besoin (un modèle peut par exemple être au niveau sur les cas généraux, mais avoir besoin d’entrainement sur les cas spécifiques). Si l’équipe n’atteint pas les objectifs attendus sur une fonctionnalité, nous devons valider l’importance de cette fonctionnalité. Si elle est très importante, des investigations serons menées pour atteindre l’objectif, sinon elle sera dépriorisée (donc nous mettrons en production sans cette fonctionnalité).
- Ne pas sous-estimer les biais : si la performance globale du modèle est bonne, il est important de vérifier son comportement auprès des différentes classes de données. Un dataset d’entrainement peut comporter des données biaisées, ces biais sont appris par l’algorithme et impactent directement la performance du modèle, entrainant de potentielles conséquences éthiques (renforcées par les biais cognitifs de ceux qui développent ces algorithmes).
- Suivre dans la durée : comme pour n’importe quel site web, le monitoring est essentiel en production, mais il y a plus d’éléments à suivre pour un produit utilisant de deep learning, notamment les performances du modèle (précision pendant le ré-entraînement, retours utilisateurs, objectifs utilisateurs) et le data drift (quand les données sur lequel s’exécute le modèle diffèrent de façon trop importante des données d'entraînement).

Le "Cross-Industry Standard Process for Data Mining" (CRISP-DM) standardise les approches les plus courantes en data mining (Ml-ops.org)
Le grand risque des projets de deep learning, c’est de s’arrêter au POC (Proof Of Concept). Un POC sert à tester et valider rapidement une hypothèse avant de se lancer dans le développement. Le problème, c’est qu’ils ont tendance à se multiplier, sans jamais aboutir à un produit mis dans les mains des utilisateurs, avec de la valeur ajoutée. Dans la plupart des cas, aucune stratégie de mise en production n’a été définie, et le POC finit ses jours au cimetière des POCs avec de nombreux confrères.
Pour ne pas gaspiller du temps et frustrer les équipes, voici cinq principes pour éviter le cimetière des POCs :
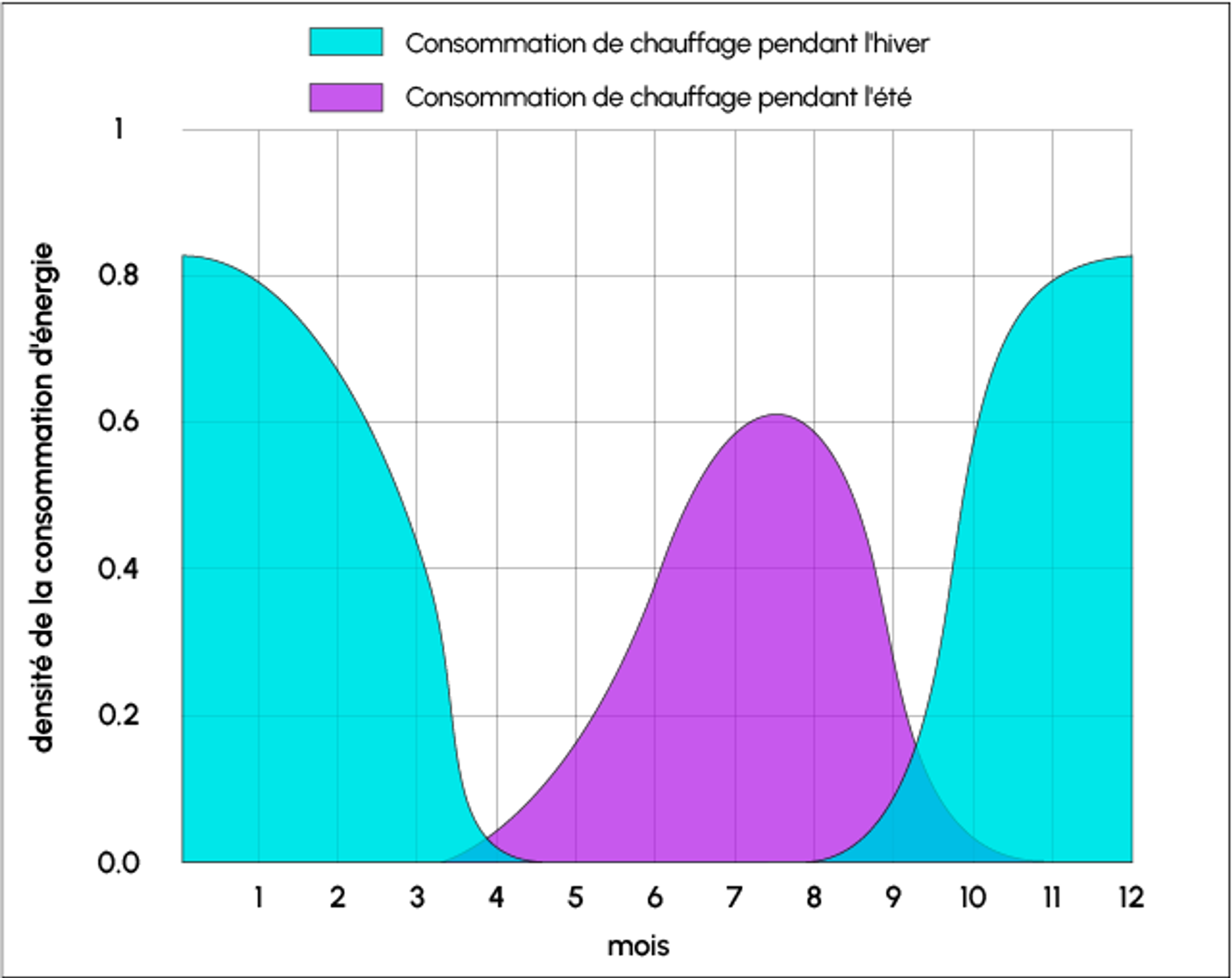
Une cause possible du data drift: la saisonnalité (DataScientest.com)